Téléchargement d’une table de données au format csv
Ouvrir la ressource suivante : https://data.angers.fr/
S’informer…
>>> Combien d’attributs ?
>>> Combien d’enregistrements ?
Etapes de la construction d’une table (en Python) à partir des données contenues dans un fichier CSV
Choisir un emplacement sur le poste de travail (Bureau, Mes documents, etc.).
Ajouter un nouveau répertoire (dossier).
Déplacer le fichier « prenoms-des-enfants-nes-a-angers.csv » qui vient d’être téléchargé dans ce dossier.
Ajouter un fichier de codes en Python dans ce répertoire (fichier qui sera vide pour l’instant).
Ouvrir ce fichier de codes en Python dans un éditeur/interpréteur (Ex: Spyder, Pyzo, etc.)
Etape 1 – Ouverture d’une ressource (= fichier csv) en lecture
Pour aller plus loin…
Téléchargement et sauvegarde du fichier csv.
import requests
URL = "https://data.angers.fr/api/explore/v2.1/catalog/datasets/prenoms-des-enfants-nes-a-angers/exports/csv"
reponse = requests.get(URL)
open("prenoms-des-enfants-nes-a-angers.csv", "wb").write(reponse.content)Les données disponibles variant d’une année à l’autre, la proposition qui suit rédigée en 2021 est en partie obsolète.
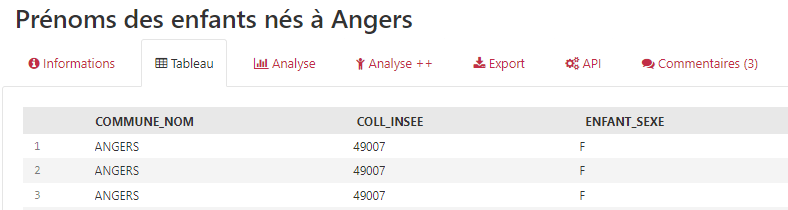
Combien d’attributs comporte la table ?
Combien d’enregistrements ?
Se rendre dans l’onglet « Export »…
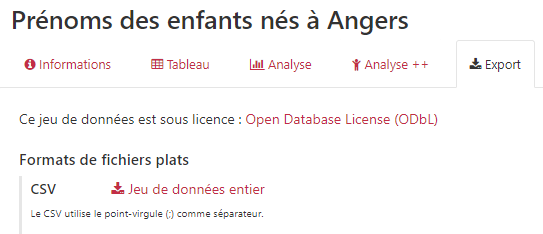
Quel est le séparateur des données dans le fichier csv ?
Cliquer sur Jeu de données entier
Construction d’une table à partir du fichier csv
Choisir un emplacement sur le poste de travail (Bureau, Mes documents, etc.).
Ajouter un nouveau répertoire (dossier).
Déplacer le fichier « prenoms-des-enfants-nes-a-angers.csv » qui vient d’être téléchargé dans ce dossier.
Ajouter un fichier de codes en Python dans ce répertoire (fichier qui sera vide pour l’instant).
Ouvrir ce fichier de codes en Python dans un éditeur/interpréteur (Ex: Spyder, Pyzo, etc.)
Ouverture d’une ressource en Python
Dans le fichier de codes en Python, saisir l’instruction suivante :
# ouverture d'une ressource
csvRess = open("prenoms-des-enfants-nes-a-angers.csv", mode="r", encoding="UTF-8")Lecture de la première ligne de données
La première ligne du fichier ‘csv’ contient les libellés des attributs (ou intitulés de colonne).
Ces données vont être mises dans une liste particulière.
# lecture de la première ligne du fichier csv # Elle contient le libellé des attributs attribLibell = csvRess.readline()
In [2]: attribLibell
Out[2]: 'COMMUNE_NOM;COLL_INSEE;ENFANT_SEXE;ENFANT_PRENOM;NOMBRE_OCCURRENCES;\ufeffANNEE\n'La variable ‘attribLibell‘ est de type ‘str’. Il s’agit de la « transformer » en liste d’éléments, en se basant sur le séparateur « ; ».
Dans le fichier de codes en Python, ajouter l’instruction suivante :# désérialisation des données
attribLibell = attribLibell.split(";")In [4]: attribLibell
Out[4]:
['COMMUNE_NOM',
'COLL_INSEE',
'ENFANT_SEXE',
'ENFANT_PRENOM',
'NOMBRE_OCCURRENCES',
'\ufeffANNEE\n']☛ Le dernier élément de la liste ‘attribLibell‘ est une chaîne de caractères qui contient des caractères ‘inutiles’ : ‘\n’ d’une part et ‘\ufeff‘ (Pour en savoir plus…) d’autre part. On veut donc les supprimer.
Dans le fichier de codes en Python, ajouter les instructions suivantes :# nettoyage des données : suppression de caractères inutiles
attribLibell[5] = attribLibell[5].replace("\n","")
attribLibell[5] = attribLibell[5].replace("\ufeff","")In [6]: attribLibell
Out[6]:
['COMMUNE_NOM',
'COLL_INSEE',
'ENFANT_SEXE',
'ENFANT_PRENOM',
'NOMBRE_OCCURRENCES',
'ANNEE']Lecture des lignes restantes
Dans le fichier de codes en Python, ajouter les instructions suivantes :# Chacune d'elles correspond à un enregistrement table = csvRess.readlines() # Fermeture de la ressource (du flux de données en lecture) csvRess.close()
In [8]: len(table)
Out[8]: 2850
In [9]: table[0]
Out[9]: 'ANGERS;49007;F;Jade;43;2013\n'# Construction finale de la table
# nE : nombre d'enregistrements
nE = len(table)
# idE : index d'un enregistrement de la table
for idE in range(nE):
# enr : enregistrement
enr = table[idE]
# désérialisation de l'enregistrement
enr = enr.split(";")
# Suppression du saut de ligne situé à la fin de la valeur du dernier attribut
enr[5] = enr[5].replace("\n","")
# conversion des chaînes de caractères du code Insee, du nombre d'occurrences et de l'année en nombres entiers
enr[1] = int(enr[1])
enr[4] = int(enr[4])
enr[5] = int(enr[5])
table[idE] = enrIn [11]: table[0]
Out[11]: ['ANGERS', 49007, 'F', 'Jade', 43, 2013]
In [12]: table[2849]
Out[12]: ['ANGERS', 49007, 'M', 'Siméon', 4, 2021]Ressources à télécharger
Archive = Fichier contenant le code Python + Fichier de données au format csv, dans un répertoire.
 << Cliquez pour plus d’informations <<
<< Cliquez pour plus d’informations <<